Просмотреть. ConvNN
Материал взят здесь http://cs231n.github.io/convolutional-networks/
Сверточные нейронные сети (CNNs / ConvNets)
Сверточные нейронные сети очень похожи на обычные нейронные сети из предыдущей главы: они состоят из нейронов, которые имеют обучаемые веса и смещения. Каждый нейрон получает некоторые входные данные, выполняет точечное произведение и, возможно, следует за ним с нелинейностью. Вся сеть по-прежнему выражает одну дифференцируемую функцию оценки: от необработанных пикселей изображения на одном конце до оценки класса на другом. И у них все еще есть функция потерь (например, SVM / Softmax) на последнем (полностью подключенном) слое, и все советы / приемы, которые мы разработали для изучения обычных нейронных сетей, по-прежнему применимы.
Так что меняется? Архитектуры ConvNet делают явное предположение, что входные данные являются изображениями, что позволяет нам кодировать определенные свойства в архитектуру. Это делает функцию пересылки более эффективной для реализации и значительно уменьшает количество параметров в сети.
Обзор архитектуры
Напомним: обычные нейронные сети. Как мы видели в предыдущей главе, нейронные сети получают входные данные (один вектор) и преобразуют его через ряд скрытых слоев . Каждый скрытый слой состоит из набора нейронов, где каждый нейрон полностью связан со всеми нейронами в предыдущем слое, и где нейроны в одном слое функционируют совершенно независимо и не имеют общих связей. Последний полностью связанный слой называется «выходным слоем» и в настройках классификации представляет баллы классов.
Обычные нейронные сети плохо масштабируются до полного изображения . В CIFAR-10 изображения имеют размер только 32x32x3 (32 в ширину, 32 в высоту, 3 цветовых канала), поэтому один полностью подключенный нейрон в первом скрытом слое обычной нейронной сети будет иметь 32 * 32 * 3 = 3072 веса. , Эта сумма все еще кажется управляемой, но ясно, что эта полностью связанная структура не масштабируется для больших изображений. Например, изображение более респектабельного размера, например 200x200x3, приведет к нейронам, которые имеют 200 * 200 * 3 = 120000 весов. Более того, мы почти наверняка хотим иметь несколько таких нейронов, поэтому параметры будут суммироваться быстро! Ясно, что это полное подключение бесполезно, и огромное количество параметров быстро приведет к переоснащению.
3D тома нейронов . Сверточные нейронные сети используют тот факт, что входные данные состоят из изображений, и они более разумно ограничивают архитектуру. В частности, в отличие от обычной нейронной сети, слои ConvNet имеют нейроны, расположенные в 3 измерениях: ширина, высота, глубина . (Обратите внимание, что глубина словаздесь относится к третьему измерению объема активации, а не к глубине полной нейронной сети, которая может относиться к общему количеству слоев в сети.) Например, входные изображения в CIFAR-10 являются входным объемом Активации, а объем имеет размеры 32x32x3 (ширина, высота, глубина соответственно). Как мы скоро увидим, нейроны в слое будут связаны только с небольшой областью слоя перед ним, а не со всеми нейронами в полностью связанном виде. Более того, конечный выходной слой для CIFAR-10 будет иметь размеры 1x1x10, потому что к концу архитектуры ConvNet мы сведем полное изображение в один вектор оценок классов, расположенных вдоль измерения глубины. Вот визуализация:


Слева: обычная трехслойная нейронная сеть. Справа: ConvNet размещает свои нейроны в трех измерениях (ширина, высота, глубина), как показано на одном из слоев. Каждый слой ConvNet преобразует объем 3D-входов в объем 3D-активаций нейронов. В этом примере красный входной слой содержит изображение, поэтому его ширина и высота будут размерами изображения, а глубина будет равна 3 (красный, зеленый, синий каналы).
ConvNet состоит из слоев. Каждый слой имеет простой API: он преобразует входной 3D-объем в выходной 3D-объем с некоторой дифференцируемой функцией, которая может иметь или не иметь параметры.
Слои, используемые для построения ConvNets
Как мы описали выше, простая ConvNet - это последовательность уровней, и каждый уровень ConvNet преобразует один объем активаций в другой с помощью дифференцируемой функции. Мы используем три основных типа слоев для построения архитектур ConvNet: сверточный уровень , объединяющий слой и полностью подключенный уровень (в точности как в обычных нейронных сетях). Мы будем складывать эти слои, чтобы сформировать полную архитектуру ConvNet .
Пример архитектуры: обзор . Мы рассмотрим более подробно ниже, но простая классификация ConvNet для CIFAR-10 может иметь архитектуру [INPUT - CONV - RELU - POOL - FC]. Более детально:
- INPUT [32x32x3] будет содержать необработанные значения пикселей изображения, в данном случае это изображение шириной 32, высотой 32 и с тремя цветными каналами R, G, B.
- Слой CONV будет вычислять выход нейронов, которые связаны с локальными областями на входе, каждый из которых вычисляет точечное произведение между их весами и небольшой областью, к которой они подключены, во входном объеме. Это может привести к объему, например, [32x32x12], если мы решили использовать 12 фильтров.
- Слой POOL выполнит операцию понижающей дискретизации вдоль пространственных измерений (ширина, высота), в результате чего получится такой объем, как [16x16x12].
- Уровень FC (т. Е. Полностью подключенный) будет вычислять баллы классов, в результате чего получится размер размера [1x1x10], где каждое из 10 чисел соответствует баллу класса, например, среди 10 категорий CIFAR-10. Как и в обычных нейронных сетях и, как следует из названия, каждый нейрон в этом слое будет связан со всеми числами в предыдущем томе.
Таким образом, ConvNets преобразовывают исходное изображение слой за слоем из исходных значений пикселей в итоговые оценки классов. Обратите внимание, что некоторые слои содержат параметры, а другие нет. В частности, слои CONV / FC выполняют преобразования, которые являются функцией не только активаций во входном объеме, но также и параметров (весов и смещений нейронов). С другой стороны, слои RELU / POOL будут реализовывать фиксированную функцию. Параметры в слоях CONV / FC будут обучаться с градиентным спуском, чтобы оценки классов, которые вычисляет ConvNet, соответствовали меткам в обучающем наборе для каждого изображения.
В итоге:
- Архитектура ConvNet в простейшем случае представляет собой список слоев, которые преобразуют объем изображения в выходной объем (например, храня оценки классов).
- Существует несколько различных типов слоев (например, CONV / FC / RELU / POOL являются наиболее популярными)
- Каждый слой принимает входной трехмерный объем и преобразует его в выходной трехмерный объем с помощью дифференцируемой функции.
- Каждый уровень может иметь или не иметь параметры (например, CONV / FC do, RELU / POOL нет)
- Каждый слой может иметь или не иметь дополнительные гиперпараметры (например, CONV / FC / POOL, а RELU - нет)

Активации примера архитектуры ConvNet. Первоначальный том хранит необработанные пиксели изображения (слева), а последний том хранит оценки классов (справа). Каждый объем активаций вдоль пути обработки отображается в виде столбца. Поскольку трехмерные тома сложно визуализировать, мы выкладываем кусочки каждого тома в строках. Объем последнего слоя содержит оценки для каждого класса, но здесь мы только визуализируем отсортированные 5 лучших результатов и печатаем метки каждого из них. Полная демонстрация в Интернете показана в заголовке нашего сайта. Показанная здесь архитектура представляет собой крошечную сеть VGG, о которой мы поговорим позже.
Теперь мы опишем отдельные слои и детали их гиперпараметров и их связности.
Сверточный слой
Уровень Conv является основным строительным блоком сверточной сети, которая выполняет большую часть вычислительной работы.
Обзор и интуиция без мозгов.Давайте сначала обсудим, что вычисляет слой CONV без аналогий мозг / нейрон. Параметры слоя CONV состоят из набора обучаемых фильтров. Каждый фильтр мал по пространству (по ширине и высоте), но простирается на всю глубину входного объема. Например, типичный фильтр в первом слое ConvNet может иметь размер 5x5x3 (то есть 5 пикселей по ширине и высоте, и 3, потому что изображения имеют глубину 3, цветовые каналы). Во время прямого прохода мы перемещаем (точнее, сворачиваем) каждый фильтр по ширине и высоте входного объема и вычисляем точечные произведения между записями фильтра и входными данными в любой позиции. Сдвигая фильтр по ширине и высоте входного объема, мы создадим двухмерную карту активации, которая дает ответы этого фильтра в каждой пространственной позиции. Наглядно, сеть будет изучать фильтры, которые активируются, когда они видят некоторый тип визуальной функции, такой как край некоторой ориентации или пятно какого-либо цвета на первом слое, или, в конечном счете, целые сотовые или колесообразные узоры на более высоких уровнях сети. Теперь у нас будет полный набор фильтров в каждом слое CONV (например, 12 фильтров), и каждый из них создаст отдельную двухмерную карту активации. Мы сложим эти карты активации вдоль измерения глубины и произведем выходной объем. и каждый из них создаст отдельную двухмерную карту активации. Мы сложим эти карты активации вдоль измерения глубины и произведем выходной объем. и каждый из них создаст отдельную двухмерную карту активации. Мы сложим эти карты активации вдоль измерения глубины и произведем выходной объем.
Мозговой взгляд . Если вы поклонник аналогий мозг / нейрон, каждая запись в трехмерном выходном объеме также может быть интерпретирована как выход нейрона, который просматривает только небольшую область на входе и разделяет параметры со всеми нейронами слева и справа пространственно (поскольку все эти числа являются результатом применения одного и того же фильтра). Теперь мы обсудим детали связности нейронов, их расположения в пространстве и их схемы совместного использования параметров.
Локальное соединение. Когда мы имеем дело с входными данными большого размера, такими как изображения, как мы видели выше, нецелесообразно соединять нейроны со всеми нейронами в предыдущем томе. Вместо этого мы подключим каждый нейрон только к локальной области входного объема. Пространственная степень этой связности представляет собой гиперпараметр, называемый рецептивным полем нейрона (что эквивалентно размеру фильтра). Степень подключения по оси глубины всегда равна глубине входного объема. Важно еще раз подчеркнуть эту асимметрию в том, как мы относимся к пространственным измерениям (ширина и высота) и измерению глубины: соединения локальны в пространстве (по ширине и высоте), но всегда полны по всей глубине входного объема.
Пример 1 . Например, предположим, что входной том имеет размер [32x32x3] (например, изображение RGB CIFAR-10). Если восприимчивое поле (или размер фильтра) составляет 5x5, то каждый нейрон в Conv-слое будет иметь весовые коэффициенты для области [5x5x3] во входном объеме, в общей сложности 5 * 5 * 3 = 75 весовых коэффициентов (и +1 параметр смещения). Обратите внимание, что степень связности по оси глубины должна быть 3, поскольку это глубина входного объема.
Пример 2 . Предположим, входной объем имел размер [16x16x20]. Затем, используя примерный размер рецептивного поля 3x3, каждый нейрон в Conv Layer теперь будет иметь в общей сложности 3 * 3 * 20 = 180 подключений к входному объему. Обратите внимание, что опять-таки подключение локально в пространстве (например, 3x3), но заполнено по глубине ввода (20).
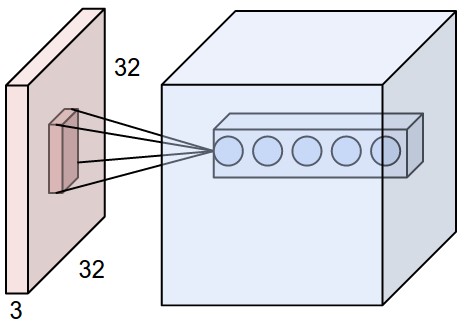

Слева: пример входного объема красным цветом (например, изображение CIFAR-10 размером 32x32x3) и пример объема нейронов в первом сверточном слое. Каждый нейрон в сверточном слое пространственно связан только с локальной областью входного объема, но на всю глубину (т. Е. Со всеми цветовыми каналами). Обратите внимание, что вдоль глубины есть несколько нейронов (в этом примере 5), все они смотрят на одну и ту же область на входе - см. Обсуждение столбцов глубины в тексте ниже. Справа: нейроны из главы «Нейронные сети» остаются неизменными: они все еще вычисляют точечное произведение их весов на вход, за которым следует нелинейность, но теперь их связность ограничена, чтобы быть локально пространственной.
Пространственное расположение . Мы объяснили связь каждого нейрона в Conv-слое с входным томом, но мы еще не обсуждали, сколько нейронов имеется в выходном объеме или как они расположены. Три гиперпараметра управляют размером выходного объема: глубина, шаг и заполнение нулями . Мы обсудим это дальше:
- Во-первых, глубина выходного объема - это гиперпараметр: он соответствует количеству фильтров, которые мы хотели бы использовать, каждый из которых учится искать что-то свое на входе. Например, если первый сверточный слой принимает в качестве входных данных необработанное изображение, то различные нейроны по измерению глубины могут активироваться при наличии различных ориентированных краев или цветных пятен. Мы будем ссылаться на набор нейронов, которые все смотрят на одну и ту же область ввода как столбец глубины (некоторые люди также предпочитают термин « волокно» ).
- Во-вторых, мы должны указать шаг, с которым мы сдвигаем фильтр. Когда шаг равен 1, мы перемещаем фильтры по одному пикселю за раз. Когда шаг равен 2 (или необычно 3 или более, хотя на практике это редко), тогда фильтры перескочат по 2 пикселя за раз, когда мы их перемещаем. Это даст меньшие объемы производства в пространстве.
- Как мы скоро увидим, иногда будет удобно заполнять входной объем нулями вокруг границы. Размер этого дополнения нулями является гиперпараметром. Приятной особенностью заполнения нулями является то, что она позволяет нам контролировать пространственный размер выходных объемов (чаще всего, как мы скоро увидим, мы будем использовать его для точного сохранения пространственного размера входного объема, чтобы ширина входа и выхода и высота одинаковы).

Иллюстрация пространственного расположения. В этом примере есть только одно пространственное измерение (ось x), один нейрон с размером восприимчивого поля F = 3, входной размер W = 5 и заполнение нулями P = 1. Слева: нейрон выделен через вход с шагом S = 1, давая выход размера (5 - 3 + 2) / 1 + 1 = 5. Справа: нейрон использует шаг S = 2, давая выход размера (5 - 3 + 2) / 2 + 1 = 3. Обратите внимание, что шаг S = 3 не может быть использован, поскольку он не будет аккуратно вписываться в объем. В терминах уравнения это можно определить, поскольку (5 - 3 + 2) = 4 не делится на 3.
В этом примере вес нейронов равен [1,0, -1] (показан справа), и его вес смещение равно нулю. Эти веса распределяются по всем желтым нейронам (см. Раздел параметров ниже).
В этом примере вес нейронов равен [1,0, -1] (показан справа), и его вес смещение равно нулю. Эти веса распределяются по всем желтым нейронам (см. Раздел параметров ниже).
гарантирует, что входной объем и выходной объем будут иметь одинаковый размер в пространстве. Таким способом очень часто используют заполнение нулями, и мы обсудим все причины, когда будем больше говорить об архитектурах ConvNet.
т. е. не целое число, указывающее, что нейроны не «аккуратно» и симметрично расположены на входе. Поэтому этот параметр гиперпараметров считается недействительным, и библиотека ConvNet может выдать исключение или заполнить нулями все остальное, чтобы подогнать его, или обрезать ввод, чтобы подогнать его, или что-то еще. Как мы увидим в разделе «Архитектура ConvNet», правильное определение размеров ConvNets таким образом, чтобы все измерения «работали», было настоящей головной болью, что значительно облегчило бы использование дополнения нулями и некоторых рекомендаций по проектированию.
выходной объем слоя Conv имел размер [55x55x96]. Каждый из 55 * 55 * 96 нейронов в этом объеме был связан с областью размером [11x11x3] во входном объеме. Более того, все 96 нейронов в каждом столбце глубины связаны с одной и той же [11x11x3] областью входа, но, конечно, с разными весами. В качестве забавы, если вы читаете реальную статью, она утверждает, что входные изображения были 224x224, что, безусловно, неверно, потому что (224 - 11) / 4 + 1 совершенно явно не является целым числом. Это смутило многих людей в истории ConvNets, и мало что известно о том, что произошло. Мое личное предположение состоит в том, что Алекс использовал заполнение нулями 3 дополнительных пикселей, которые он не упоминает в статье.
Обмен параметрами. Схема совместного использования параметров используется в сверточных слоях для управления количеством параметров. Используя приведенный выше реальный пример, мы видим, что в первом слое Conv есть 55 * 55 * 96 = 290 400 нейронов, и каждый имеет 11 * 11 * 3 = 363 веса и 1 смещение. В совокупности это составляет до 290400 * 364 = 105 705 600 параметров только на первом уровне ConvNet. Понятно, что это число очень велико.
Оказывается, мы можем значительно сократить количество параметров, сделав одно разумное предположение: если один объект полезен для вычисления в некоторой пространственной позиции (x, y), то он также должен быть полезен для вычисления в другой позиции (x2). , у2). Другими словами, обозначая один двумерный срез глубины как срез глубины(например, объем размером [55x55x96] имеет 96 срезов глубины, каждый размером [55x55]), мы собираемся ограничить нейроны в каждом срезе глубины, чтобы использовать одинаковые веса и смещения. С этой схемой совместного использования параметров первый Conv Layer в нашем примере теперь будет иметь только 96 уникальных наборов весов (по одному для каждого среза глубины), в общей сложности 96 * 11 * 11 * 3 = 34 848 уникальных весов или 34 944 параметра ( +96 уклонов). Кроме того, все 55 * 55 нейронов в каждом срезе глубины теперь будут использовать одни и те же параметры. На практике во время обратного распространения каждый нейрон в объеме будет вычислять градиент для его весов, но эти градиенты будут складываться по каждому срезу глубины и обновлять только один набор весов на срез.
Обратите внимание, что если все нейроны в одном срезе глубины используют один и тот же вектор весов, то прямой проход слоя CONV в каждом срезе глубины может быть вычислен как свертка весов нейрона с входным объемом (отсюда и название: сверточный слой ). Вот почему принято называть наборы весов фильтром (или ядром ), который свернут с входными данными.

Примеры фильтров, изученных Krizhevsky et al. Каждый из 96 фильтров, показанных здесь, имеет размер [11x11x3], и каждый из них разделен нейронами 55 * 55 в одном срезе глубины. Обратите внимание, что предположение о совместном использовании параметров является относительно разумным: если обнаружение горизонтального края важно в некотором месте на изображении, оно должно быть интуитивно полезно и в другом месте из-за трансляционно-инвариантной структуры изображений. Поэтому нет необходимости переучиваться для обнаружения горизонтального края в каждом из 55 * 55 различных мест в выходном объеме слоя Conv.
Обратите внимание, что иногда предположение о совместном использовании параметров может не иметь смысла. Это особенно актуально, когда входные изображения в ConvNet имеют определенную центрированную структуру, где, например, следует ожидать, что на одной стороне изображения должны быть изучены совершенно другие функции, чем на другой. Одним из практических примеров является случай, когда входными данными являются лица, центрированные по изображению. Вы можете ожидать, что различные специфические для глаза или для волос особенности могут (и должны) быть изучены в разных пространственных местах. В этом случае обычно ослабляют схему совместного использования параметров и вместо этого просто называют слой локально связанным слоем .
Numpy примеры. Чтобы сделать обсуждение выше более конкретным, давайте выразим те же идеи, но в коде и на конкретном примере. Предположим, что входной объем является массивом NumPy
X. Затем:- Колонка глубины (или волокно ) в положении
(x,y)будет активированиемX[x,y,:]. - Глубина среза , или , что эквивалентно карту активации на глубине
dбудет активированиеX[:,:,d].
XX.shape: (11,11,4)VV[0,0,0] = np.sum(X[:5,:5,:] * W0) + b0V[1,0,0] = np.sum(X[2:7,:5,:] * W0) + b0V[2,0,0] = np.sum(X[4:9,:5,:] * W0) + b0V[3,0,0] = np.sum(X[6:11,:5,:] * W0) + b0
Помните, что в numpy приведенная
*выше операция обозначает поэлементное умножение между массивами. Также обратите внимание, что вектор весов W0является вектором весов этого нейрона и b0является смещением. Здесь W0предполагается, что он имеет форму W0.shape: (5,5,4), поскольку размер фильтра равен 5, а глубина входного объема равна 4. Обратите внимание, что в каждой точке мы вычисляем скалярное произведение, как было показано ранее в обычных нейронных сетях. Кроме того, мы видим, что мы используем тот же вес и смещение (из-за совместного использования параметров), и где размеры по ширине увеличиваются с шагом 2 (т. Е. Шаг). Чтобы построить вторую карту активации в выходном объеме, мы должны иметь:V[0,0,1] = np.sum(X[:5,:5,:] * W1) + b1V[1,0,1] = np.sum(X[2:7,:5,:] * W1) + b1V[2,0,1] = np.sum(X[4:9,:5,:] * W1) + b1V[3,0,1] = np.sum(X[6:11,:5,:] * W1) + b1V[0,1,1] = np.sum(X[:5,2:7,:] * W1) + b1(пример движения вдоль у)V[2,3,1] = np.sum(X[4:9,6:11,:] * W1) + b1(или вдоль обоих)
где мы видим, что мы индексируем во второе измерение глубины в
V(по индексу 1), потому что мы вычисляем вторую карту активации, и что W1теперь используется другой набор параметров ( ). В приведенном выше примере мы для краткости опускаем некоторые другие операции, которые Conv Layer будет выполнять для заполнения других частей выходного массива V. Кроме того, напомним, что за этими картами активации часто следуют поэлементно с помощью функции активации, такой как ReLU, но здесь это не показано.
Резюме . Подводя итог, Conv Layer:
- Требуется четыре гиперпараметра:
Реализация как матричное умножение . Обратите внимание, что операция свертки, по существу, выполняет точечные произведения между фильтрами и локальными областями ввода. Обычный шаблон реализации уровня CONV состоит в том, чтобы воспользоваться этим фактом и сформулировать прямой проход сверточного уровня в виде одной большой матрицы, умноженной следующим образом:
- Локальные области во входном изображении растягиваются в столбцы в операции, обычно называемой im2col . Например, если входной сигнал равен [227x227x3] и его нужно свернуть с фильтрами 11x11x3 на шаге 4, тогда мы будем брать [11x11x3] блоков пикселей на входе и растягивать каждый блок в вектор-столбец размером 11 * 11 *. 3 = 363. Итерация этот процесс на входе в шаге 4 дает (227-11) / 4 + 1 = 55 места вдоль обоих ширины и высоты, что приводит к выходной матрице
X_colиз im2col размера [363 х 3025], где каждый столбец - это вытянутое восприимчивое поле, и их всего 55 * 55 = 3025. Обратите внимание, что, поскольку рецептивные поля перекрываются, каждое число во входном объеме может дублироваться в нескольких отдельных столбцах. - Веса слоя CONV аналогично растягиваются в ряды. Например, если имеется 96 фильтров размера [11x11x3], это даст матрицу
W_rowразмера [96 x 363]. - Результат свертки теперь эквивалентен выполнению одного большого умножения матрицы
np.dot(W_row, X_col), которое оценивает скалярное произведение между каждым фильтром и каждым местоположением восприимчивого поля. В нашем примере результат этой операции будет [96 x 3025], что даст выход точечного произведения каждого фильтра в каждом месте. - В конечном итоге результат должен быть преобразован обратно в соответствующий выходной размер [55x55x96].
Недостатком этого подхода является то, что он может использовать много памяти, поскольку некоторые значения во входном томе реплицируются несколько раз в
X_col. Однако преимущество заключается в том, что существует множество очень эффективных реализаций Matrix Multiplication, которыми мы можем воспользоваться (например, в обычно используемом API BLAS ). Более того, ту же идею im2col можно использовать для выполнения операции объединения, о которой мы поговорим далее.
Обратное распространение. Обратный проход для операции свертки (как для данных, так и для весов) также является сверткой (но с пространственно-перевернутыми фильтрами). Это легко вывести в одномерном случае на игрушечном примере (пока не расширен).
1x1 свертка . Кроме того, в нескольких работах используются свертки 1x1, что впервые было исследовано Сетью в Сети . Некоторые люди сначала смущаются, видя свертки 1x1, особенно когда они происходят из фона обработки сигналов. Обычно сигналы являются двумерными, поэтому свертки 1x1 не имеют смысла (это просто точечное масштабирование). Однако в ConvNets это не так, потому что нужно помнить, что мы работаем с трехмерными объемами и что фильтры всегда распространяются на всю глубину входного объема. Например, если входной сигнал равен [32x32x3], то выполнение свертки 1x1 будет эффективно производить трехмерные точечные произведения (поскольку глубина ввода составляет 3 канала).
Расширенные свертки. Недавняя разработка (например, см. Статью Фишера Ю и Владлена Колтуна ) состоит во введении еще одного гиперпараметра в слой CONV, который называется дилатацией . До сих пор мы обсуждали только смежные фильтры CONV. Тем не менее, возможно иметь фильтры с пробелами между ячейками, которые называются дилатацией. В качестве примера, в одном измерении фильтр
wразмера 3 бы вычислить за ввод xследующего: w[0]*x[0] + w[1]*x[1] + w[2]*x[2]. Это расширение 0. Для дилатации 1 фильтр вместо этого будет вычислятьw[0]*x[0] + w[1]*x[2] + w[2]*x[4]; Другими словами, между приложениями существует разрыв в 1. Это может быть очень полезно в некоторых настройках для использования в сочетании с 0-расширенными фильтрами, потому что оно позволяет объединять пространственную информацию между входами гораздо агрессивнее с меньшим количеством слоев. Например, если вы сложите два слоя 3x3 CONV друг на друга, то вы можете убедить себя, что нейроны на 2-м слое являются функцией патча входа 5x5 (мы бы сказали, что эффективное рецептивное поле этих нейронов 5x5). Если мы будем использовать расширенные свертки, то это эффективное рецептивное поле будет расти гораздо быстрее.Слой пула
Обычно в последовательную архитектуру ConvNet периодически вставляют промежуточный уровень пула между пулами. Его функция заключается в постепенном уменьшении пространственного размера представления, чтобы уменьшить количество параметров и вычислений в сети, и, следовательно, также контролировать перенастройку. Слой пула работает независимо на каждом срезе глубины входа и изменяет его размер в пространстве, используя операцию MAX. Наиболее распространенной формой является объединяющий слой с фильтрами размером 2x2, нанесенными с шагом 2 нисходящих выборок на каждый срез глубины на входе на 2 по ширине и высоте, отбрасывая 75% активаций. Каждая операция MAX в этом случае будет принимать максимум 4 числа (небольшая область 2x2 в некотором срезе глубины). Размер по глубине остается неизменным. В целом, слой пула:
- Требуются два гиперпараметра:
- Вводит нулевые параметры, поскольку он вычисляет фиксированную функцию ввода
- Для пулов слоев не принято дополнять ввод с помощью заполнения нулями.
Общий пул . В дополнение к максимальному объединению в пул модули могут также выполнять другие функции, такие как среднее объединение или даже объединение L2-нормы . Среднее объединение часто использовалось исторически, но в последнее время оно не пользуется популярностью по сравнению с операцией максимального объединения, которая, как было показано, работает лучше на практике.
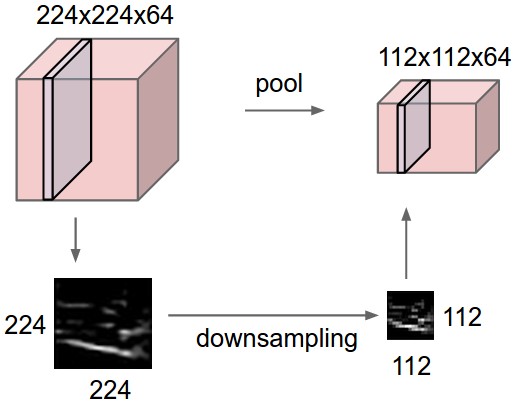

Слой объединения сокращает объем пространственно, независимо в каждом срезе глубины входного объема. Слева: в этом примере входной объем размером [224x224x64] объединяется с фильтром размера 2, шаг 2 в выходной объем размером [112x112x64]. Обратите внимание, что объемная глубина сохраняется. Справа: наиболее распространенной операцией понижающей дискретизации является максимальная, приводящая к максимальному объединению , которая здесь показана с шагом 2. То есть каждый максимум берется за 4 числа (маленький квадрат 2х2).
Обратное распространение . Вспомните из главы о обратном распространении, что обратный проход для операции max (x, y) имеет простую интерпретацию, поскольку он направляет только градиент на вход, имеющий наибольшее значение в прямом проходе. Следовательно, во время прямого прохода уровня объединения обычно отслеживают индекс максимальной активации (иногда также называемый коммутаторами ), чтобы градиентная маршрутизация была эффективной во время обратного распространения.
Избавляемся от объединения . Многим людям не нравится операция объединения и думают, что мы можем обойтись без этого. Например, « Стремление к простоте: вся сверточная сеть» предлагает отказаться от пула, отдавая предпочтение архитектуре, которая состоит только из повторяющихся слоев CONV. Чтобы уменьшить размер представления, они предлагают время от времени использовать больший шаг в слое CONV. Было также обнаружено, что отбрасывание уровней объединения важно для обучения хороших генеративных моделей, таких как вариационные автоэнкодеры (VAE) или генеративные состязательные сети (GAN). Вполне вероятно, что в будущих архитектурах будет очень мало или вообще не будет слоев объединения.
Слой нормализации
Многие типы слоев нормализации были предложены для использования в архитектурах ConvNet, иногда с намерением реализовать схемы ингибирования, наблюдаемые в биологическом мозге. Однако с тех пор эти слои перестали пользоваться популярностью, поскольку на практике их вклад был минимальным, если он вообще имел место. Для различных типов нормализации, см. Обсуждение в API библиотеки cuda-convnet Алекса Крижевского .
Полностью связанный слой
Нейроны в полностью связанном слое имеют полные соединения со всеми активациями в предыдущем слое, как это видно в обычных нейронных сетях. Их активации, следовательно, могут быть вычислены с умножением матрицы с последующим смещением смещения. См. Раздел « Нейронные сети » для получения дополнительной информации.
Преобразование слоев FC в слои CONV
Стоит отметить, что единственное различие между слоями FC и CONV состоит в том, что нейроны в слое CONV связаны только с локальной областью на входе, и что многие из нейронов в объеме объема CONV имеют общие параметры. Однако нейроны в обоих слоях все еще вычисляют точечные произведения, поэтому их функциональная форма идентична. Следовательно, оказывается, что возможно конвертировать между слоями FC и CONV:
- Для любого уровня CONV существует уровень FC, который реализует ту же функцию пересылки. Весовая матрица будет большой матрицей, которая в основном равна нулю, за исключением определенных блоков (из-за локальной возможности соединения), где веса во многих блоках равны (из-за совместного использования параметров).
- поскольку только один столбец глубины «умещается» во входном объеме, давая результат, идентичный исходному слою FC.
FC-> CONV конвертация . Из этих двух преобразований возможность преобразования слоя FC в слой CONV особенно полезна на практике. Рассмотрим архитектуру ConvNet, которая принимает изображение 224x224x3, а затем использует серию слоев CONV и слоев POOL, чтобы уменьшить изображение до объема активаций размером 7x7x512 (в архитектуре AlexNet, которую мы увидим позже, это делается с помощью 5 объединяющих слоев, которые уменьшают входные данные пространственно с коэффициентом два каждый раз, получая окончательный размер пространства 224/2/2/2/2/2 = 7). Оттуда AlexNet использует два слоя FC размером 4096 и, наконец, последние слои FC с 1000 нейронов, которые вычисляют оценки класса. Мы можем преобразовать каждый из этих трех слоев FC в слои CONV, как описано выше:
Например, если изображение размером 224x224 дает объем размером [7x7x512], то есть уменьшение на 32, то пересылка изображения размером 384x384 через преобразованную архитектуру даст эквивалентный объем по размеру [12x12x512], поскольку 384/32 = 12. Выполнение следующих 3 слоев CONV, которые мы только что преобразовали из слоев FC, теперь дало бы конечный объем размера [6x6x1000], поскольку (12 - 7) / 1 + 1 = 6. Обратите внимание, что вместо одного вектора оценок классов размером [1x1x1000], теперь мы получаем целый массив баллов 6x6 по изображению 384x384.
Независимая оценка исходного ConvNet (со слоями FC) по кадрам 224x224 изображения 384x384 с шагом 32 пикселя дает идентичный результат для перенаправления конвертированной ConvNet один раз.
Естественно, что пересылка конвертированной ConvNet за один раз намного эффективнее, чем перебор исходной ConvNet по всем этим 36 местоположениям, поскольку 36 оценок разделяют вычисления. Этот прием часто используется на практике для повышения производительности, когда, например, обычно изменяют размер изображения, чтобы увеличить его, используют преобразованную ConvNet для оценки баллов классов во многих пространственных положениях, а затем усредняют баллы классов.
Наконец, что, если мы хотим эффективно применить оригинальную ConvNet к изображению, но с шагом менее 32 пикселей? Мы могли бы достичь этого с несколькими проходами вперед. Например, обратите внимание, что если мы хотим использовать шаг в 16 пикселей, мы можем сделать это, объединив объемы, полученные путем двукратной пересылки ConvNet: сначала поверх исходного изображения, а затем поверх изображения, но с пространственным смещением изображения на 16 пикселей. по ширине и высоте.
- Блокнот IPython по сетевой хирургии показывает, как выполнить преобразование на практике в коде (с использованием Caffe)
Архитектуры ConvNet
Мы видели, что сверточные сети обычно состоят только из трех типов слоев: CONV, POOL (мы предполагаем максимальный пул, если не указано иное) и FC (сокращение от полностью подключенных). Мы также явно напишем функцию активации RELU как слой, который применяет поэлементную нелинейность. В этом разделе мы обсудим, как они обычно объединяются в целые ConvNets.
Шаблоны слоев
Наиболее распространенная форма архитектуры ConvNet укладывает несколько слоев CONV-RELU, следует за ними со слоями POOL и повторяет этот шаблон до тех пор, пока изображение не будет пространственно объединено до небольшого размера. В какой-то момент часто происходит переход к полностью соединенным слоям. Последний полностью связанный слой содержит выходные данные, такие как оценки класса. Другими словами, наиболее распространенная архитектура ConvNet следует шаблону:
INPUT -> [[CONV -> RELU]*N -> POOL?]*M -> [FC -> RELU]*K -> FC
где
*указывает на повторение, а POOL?указывает на необязательный уровень пула. Более того, N >= 0(и обычно N <= 3) M >= 0,, K >= 0(и обычно K < 3). Например, вот некоторые распространенные архитектуры ConvNet, которые вы можете видеть по следующему шаблону:INPUT -> FC, реализует линейный классификатор. HereN = M = K = 0.INPUT -> CONV -> RELU -> FCINPUT -> [CONV -> RELU -> POOL]*2 -> FC -> RELU -> FC, Здесь мы видим, что существует один слой CONV между каждым слоем POOL.INPUT -> [CONV -> RELU -> CONV -> RELU -> POOL]*3 -> [FC -> RELU]*2 -> FCЗдесь мы видим два слоя CONV, сложенных перед каждым слоем POOL. Как правило, это хорошая идея для больших и более глубоких сетей, поскольку несколько стековых слоев CONV могут развить более сложные функции входного объема перед разрушительной операцией объединения.
Предпочитайте стопку небольших фильтров CONV одному слою CONV большого восприимчивого поля, Предположим, что вы укладываете три слоя 3x3 CONV друг на друга (с нелинейностями между ними, конечно). При таком расположении каждый нейрон на первом слое CONV имеет вид 3х3 входного объема. Нейрон на втором слое CONV имеет представление 3x3 первого слоя CONV и, следовательно, расширение представления 5x5 входного объема. Точно так же нейрон на третьем слое CONV имеет вид 3x3 второго слоя CONV и, следовательно, вид 7x7 входного объема. Предположим, что вместо этих трех слоев 3x3 CONV мы хотели использовать только один слой CONV с 7x7 рецептивными полями. Эти нейроны будут иметь размер восприимчивого поля входного объема, который идентичен по пространственному размеру (7x7), но с несколькими недостатками. Во-первых, нейроны будут вычислять линейную функцию на входе, в то время как три стопки слоев CONV содержат нелинейности, которые делают их функции более выразительными. Во-вторых, если предположить, что все тома имеютпараметры. Интуитивно понятно, что укладка слоев CONV с крошечными фильтрами в отличие от наличия одного слоя CONV с большими фильтрами позволяет нам выразить более мощные функции ввода и с меньшим количеством параметров. В качестве практического недостатка нам может потребоваться больше памяти для хранения всех результатов промежуточного уровня CONV, если мы планируем обратное распространение.
Последние вылеты. Следует отметить, что традиционная парадигма линейного списка слоев недавно была подвергнута сомнению в начальных архитектурах Google, а также в современных (современных) остаточных сетях Microsoft Research Asia. Оба из них (см. Подробности ниже в разделе тематических исследований) имеют более сложные и разные структуры связи.
На практике: используйте все, что лучше всего работает в ImageNet . Если вы немного устали от размышлений об архитектурных решениях, вам будет приятно узнать, что в 90% или более приложений вам не нужно беспокоиться об этом. Мне нравится резюмировать этот пункт как « не будь героем »: вместо того, чтобы бросать свою собственную архитектуру на проблему, вы должны взглянуть на любую архитектуру, которая в настоящее время лучше всего работает в ImageNet, загрузить предварительно обученную модель и настроить ее на своих данных. Вам редко когда-либо придется обучать ConvNet с нуля или создавать его с нуля. Я также сделал это в школе глубокого обучения .
Шаблоны размеров слоя
До сих пор мы опускали упоминания об общих гиперпараметрах, используемых в каждом из слоев в ConvNet. Сначала мы сформулируем общие практические правила для определения размеров архитектур, а затем следуем правилам с обсуждением обозначений:
Входной слой (который содержит изображение) должен быть кратен 2 много раз. Общие числа включают 32 (например, CIFAR-10), 64, 96 (например, STL-10) или 224 (например, общие ConvNets ImageNet), 384 и 512.
сохраняет размер ввода. Если вам нужно использовать фильтры большего размера (например, 7x7 или около того), это обычно можно увидеть на самом первом конвульсовом слое, который смотрит на входное изображение.
Уменьшение размеров головных болей. Представленная выше схема приятна тем, что все слои CONV сохраняют пространственный размер их входных данных, тогда как только слои POOL отвечают за пространственную дискретизацию объемов. В альтернативной схеме, в которой мы используем шаги больше 1 или не дополняем нулями входные данные в слоях CONV, нам пришлось бы очень тщательно отслеживать объемы ввода по всей архитектуре CNN и убедиться, что все шаги и фильтры «работают». out ”, и что архитектура ConvNet имеет красивую и симметричную структуру.
Зачем использовать шаг 1 в CONV? Меньшие шаги работают лучше на практике. Кроме того, как уже упоминалось, шаг 1 позволяет нам оставить всю пространственную понижающую дискретизацию для слоев POOL, причем слои CONV только трансформируют входной объем по глубине.
Зачем использовать прокладку? В дополнение к вышеупомянутому преимуществу сохранения постоянных пространственных размеров после CONV, это фактически повышает производительность. Если бы слои CONV не вводили нулями входные данные и выполняли только действительные свертки, то размер томов уменьшился бы на небольшую величину после каждого CONV, и информация на границах была бы «размыта» слишком быстро.
Компромисс на основе ограничений памяти.В некоторых случаях (особенно на ранних стадиях в архитектурах ConvNet) объем памяти может очень быстро увеличиваться с помощью эмпирических правил, представленных выше. Например, фильтрация изображения 224x224x3 с тремя слоями CONV 3x3 с 64 фильтрами каждый и заполнением 1 создаст три тома активации размером [224x224x64]. Это составляет в общей сложности около 10 миллионов активаций или 72 МБ памяти (на изображение, как для активаций, так и для градиентов). Поскольку графические процессоры часто являются узким местом в памяти, может потребоваться компромисс. На практике люди предпочитают идти на компромисс только на первом уровне CONV сети. Например, одним из компромиссов может быть использование первого слоя CONV с размерами фильтров 7x7 и шагом 2 (как видно в сети ZF). В качестве другого примера, AlexNet использует фильтры размером 11x11 и шагом 4.
Тематические исследования
Существует несколько архитектур в области сверточных сетей, которые имеют имя. Наиболее распространенными являются:
- LeNet . Первые успешные приложения Convolutional Networks были разработаны Yann LeCun в 1990-х годах. Из них наиболее известной является архитектура LeNet, которая использовалась для чтения почтовых индексов, цифр и т. Д.
- AlexNet . Первой работой, которая популяризировала Convolutional Networks в Computer Vision, была AlexNet , разработанная Алексом Крижевским, Ильей Суцкевером и Джеффом Хинтоном. AlexNet был представлен к конкурсу ImageNet ILSVRC в 2012 году и значительно превзошел второго, занявшего второе место (ошибка 5 лучших в 16% по сравнению с участником, занявшим второе место с ошибкой 26%). Сеть имела архитектуру, очень похожую на LeNet, но была глубже, больше и содержала сверточные слои, накладываемые друг на друга (ранее было обычным делом иметь только один слой CONV, за которым всегда сразу следовал слой POOL).
- ZF Net . Победителем ILSVRC 2013 стала сверточная сеть от Мэтью Цейлера и Роба Фергуса. Он стал известен как ZFNet (сокращение от Zeiler & Fergus Net). Это было улучшением в AlexNet за счет изменения гиперпараметров архитектуры, в частности за счет увеличения размера средних сверточных слоев и уменьшения шага и размера фильтра на первом слое.
- GoogLeNet . Победителем ILSVRC 2014 стала сверточная сеть от Szegedy et al. от гугла. Его основным вкладом была разработка начального модуля, который значительно сократил количество параметров в сети (4M, по сравнению с AlexNet с 60M). Кроме того, в этой статье используется средний пул вместо полностью подключенных слоев в верхней части ConvNet, что исключает большое количество параметров, которые, кажется, не имеют большого значения. Есть также несколько последующих версий GoogLeNet, последняя из которых - Inception-v4 .
- VGGNet . Второе место в ILSVRC 2014 заняла сеть от Карена Симоняна и Эндрю Циссермана, которая стала известной как VGGNet . Его основной вклад заключался в том, чтобы показать, что глубина сети является критическим компонентом для хорошей производительности. Их последняя лучшая сеть содержит 16 уровней CONV / FC и, что привлекательно, обладает чрезвычайно однородной архитектурой, которая выполняет только 3x3 свертки и 2x2 объединения от начала до конца. Их предварительно обученная модельдоступно для подключи и играй в кафе. Недостатком VGGNet является то, что его оценка обходится дороже и использует гораздо больше памяти и параметров (140 МБ). Большинство этих параметров находятся в первом полностью связанном слое, и с тех пор было обнаружено, что эти уровни FC могут быть удалены без снижения производительности, что значительно сокращает количество необходимых параметров.
- ResNet . Остаточная сеть, разработанная Kaiming He et al. был победителем ILSVRC 2015. Он имеет специальные пропускаемые соединения и интенсивное использование нормализации партии . В архитектуре также отсутствуют полностью подключенные слои в конце сети. Читатель также ссылается на презентацию Кайминга ( видео , слайды ) и некоторые недавние эксперименты, которые воспроизводят эти сети в Факеле. ResNets в настоящее время являются современными моделями Convolutional Neural Network и являются выбором по умолчанию для использования ConvNets на практике (по состоянию на 10 мая 2016 года). В частности, также можно увидеть более свежие разработки, которые настраивают оригинальную архитектуруKaiming He et al. Отображения идентичности в глубоких остаточных сетях (опубликовано в марте 2016 г.).
VGGNet подробно . Давайте разберем VGGNet более подробно в качестве примера. Вся сеть VGGNet состоит из слоев CONV, которые выполняют свертки 3x3 с шагом 1 и площадкой 1, и из слоев POOL, которые выполняют максимальное объединение 2x2 с шагом 2 (и без заполнения). Мы можем записать размер представления на каждом шаге обработки и отслеживать как размер представления, так и общее количество весов:
INPUT: [224x224x3] memory: 224*224*3=150K weights: 0
CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*3)*64 = 1,728
CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*64)*64 = 36,864
POOL2: [112x112x64] memory: 112*112*64=800K weights: 0
CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*64)*128 = 73,728
CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*128)*128 = 147,456
POOL2: [56x56x128] memory: 56*56*128=400K weights: 0
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*128)*256 = 294,912
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824
POOL2: [28x28x256] memory: 28*28*256=200K weights: 0
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*256)*512 = 1,179,648
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296
POOL2: [14x14x512] memory: 14*14*512=100K weights: 0
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
POOL2: [7x7x512] memory: 7*7*512=25K weights: 0
FC: [1x1x4096] memory: 4096 weights: 7*7*512*4096 = 102,760,448
FC: [1x1x4096] memory: 4096 weights: 4096*4096 = 16,777,216
FC: [1x1x1000] memory: 1000 weights: 4096*1000 = 4,096,000
TOTAL memory: 24M * 4 bytes ~= 93MB / image (only forward! ~*2 for bwd)
TOTAL params: 138M parameters
Как и в случае со сверточными сетями, обратите внимание, что большая часть памяти (а также время вычислений) используется на ранних слоях CONV, и что большинство параметров находятся на последних слоях FC. В этом конкретном случае первый слой FC содержит 100 миллионов весов из общего числа 140 миллионов.
Вычислительные соображения
Самым большим узким местом, о котором следует помнить при построении архитектур ConvNet, является узкое место в памяти. Многие современные графические процессоры имеют ограничение в 3/4/6 ГБ памяти, а лучшие графические процессоры имеют около 12 ГБ памяти. Есть три основных источника памяти для отслеживания:
- От размеров промежуточного объема: это необработанное количество активаций на каждом уровне ConvNet, а также их градиенты (одинакового размера). Обычно большинство активаций находятся на более ранних уровнях ConvNet (то есть на первых уровнях Conv). Они хранятся вокруг, потому что они необходимы для обратного распространения, но умная реализация, которая запускает ConvNet только во время тестирования, может в принципе уменьшить это на огромное количество, сохраняя только текущие активации на любом уровне и отбрасывая предыдущие активации на уровнях ниже ,
- От размеров параметров: это числа, которые содержат параметры сети , их градиенты во время обратного распространения, и обычно также пошаговый кэш, если оптимизация использует импульс, Adagrad или RMSProp. Следовательно, память для хранения одного вектора параметров обычно должна быть умножена не менее чем на 3 раза.
- Каждая реализация ConvNet должна поддерживать разную память, такую как пакеты данных изображения, возможно, их расширенные версии и т. Д.
Как только вы получите приблизительную оценку общего количества значений (для активаций, градиентов и разного), число должно быть преобразовано в размер в ГБ. Возьмите количество значений, умножьте на 4, чтобы получить необработанное число байтов (поскольку каждая плавающая точка составляет 4 байта, или, может быть, на 8 для двойной точности), а затем разделите на 1024 несколько раз, чтобы получить объем памяти в КБ, МБ и, наконец, ГБ. Если ваша сеть не подходит, обычная эвристика для «подгонки» - это уменьшение размера пакета, так как большая часть памяти обычно используется активациями.

Комментарии
Отправить комментарий