Создание сверточных нейронных сетей с нуля
Источник https://towardsdatascience.com/a-guide-to-convolutional-neural-networks-from-scratch-f1e3bfc3e2de
Создание сверточных нейронных сетей с нуля
Сверточные слои:
Способ количественной оценки влияния каждого фильтра состоял бы в том, чтобы вычислить оценку для каждого изображения и каждого фильтра. Чем ближе оценка к единице, тем больше функция влияет на ввод.
Одна проблема с вычислительными свертками заключается в том, что размер фильтра, размер шага и размер изображения могут быть асимметричными. Например, если у вас есть изображение 32x32x3, фильтр 7x7x3 и шаг 1, фильтр не сможет просматривать все пиксели изображения. Нулевое заполнение решает эту проблему, добавляя нули по периметру изображения. Нулевое заполнение также является хорошей практикой, поскольку позволяет контролировать размер выходных томов. Это гарантирует, что края не исчезают слишком быстро, а пространственный размер и структура входного объема сохраняются. Таким образом, вы можете проектировать больше, более глубокие сети. Нулевое заполнение - это еще один способ убедиться, что из изображения извлечены лучшие данные, чтобы сеть могла достичь наилучших результатов.

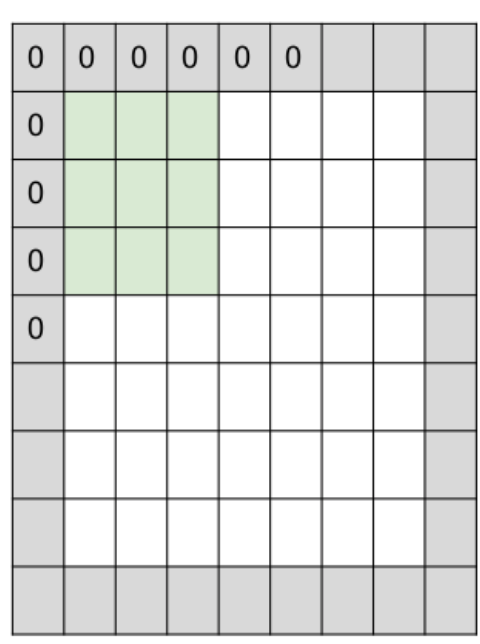
Как вычислить свертку:
- Умножьте каждый пиксель изображения на вес, а затем на пиксель фильтра (точечный продукт)
- добавить их
- разделить на общее количество пикселей в фильтре
Реализация не слишком далеко от этих шагов. После того, как вы установили значения для размера шага, заполнения нулями и выходных данных, вы вычисляете свертку и сохраняете вычисленные значения в кеше, чтобы к ним снова можно было получить доступ для обратного распространения.

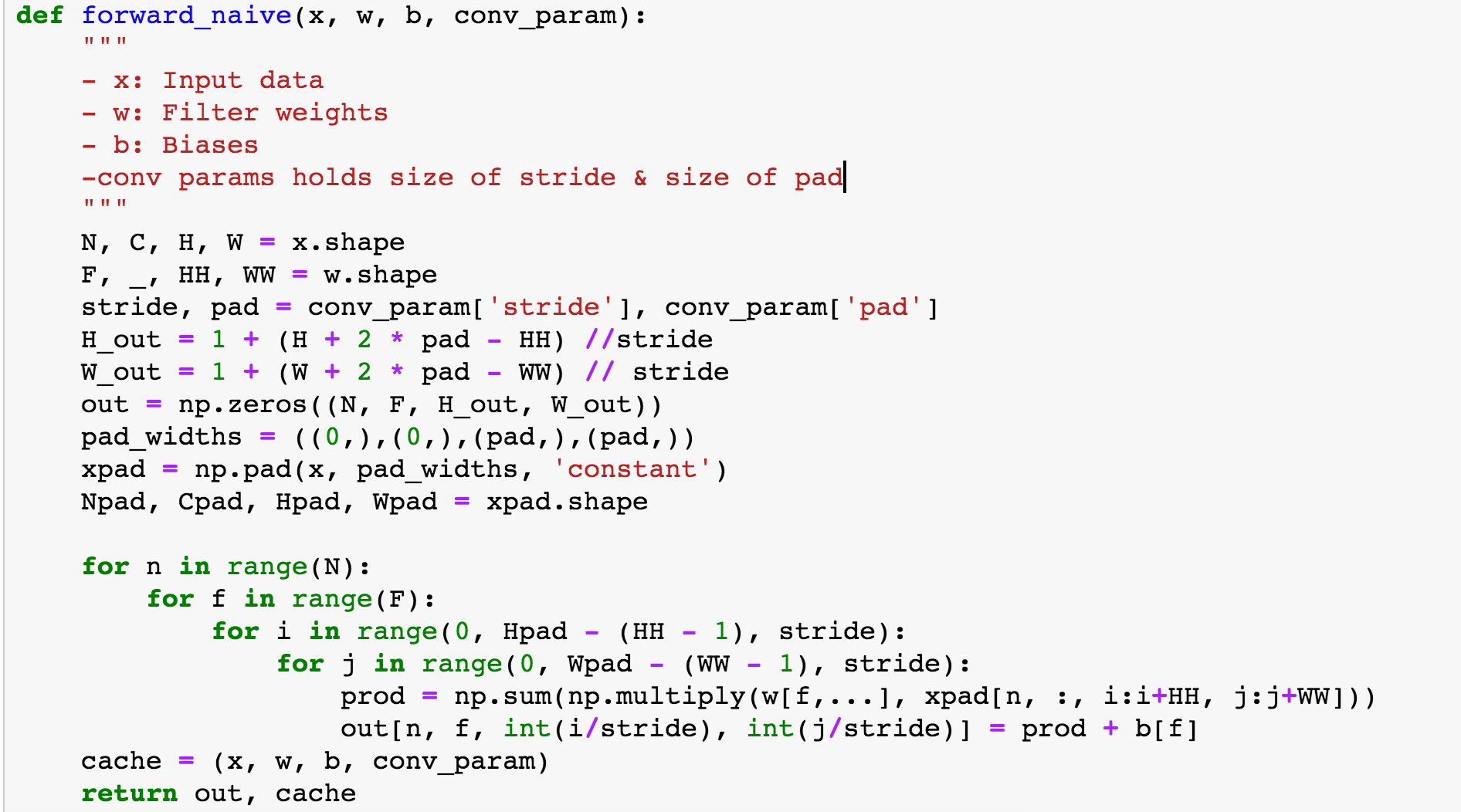
Теперь вы можете понять, почему у CNN репутация вычислительных свиней. Этот тип реализации, как правило, не будет использоваться в больших масштабах, но смысл этого проекта - глубоко погрузиться в то, что на самом деле делает CNN.
объединение
Процесс объединения принимает входные данные и уменьшает их размер, сохраняя при этом наиболее важную информацию во входных данных. Объединение в пул уменьшает шумовые параметры во время вычислений, что в свою очередь контролирует переоснащение. Этот процесс берет фильтр 2x2 с шагом 2 по входу и выбирает входной пиксель с максимальным значением и помещает этот пиксель в выходной сигнал уменьшенного размера. Объединение в пул уменьшает размер входа с W1xH1xD1 до нового выхода с размером W2 = (размер W1) / шаг + 1, (размер H1) / шаг + 1 и D2 = D1. Это избавляет от 75% предыдущего ввода. Остальные 25% являются входными данными, которые наиболее похожи на пиксели в конкретном фильтре. Опять же, этот процесс дополнительно изолирует наиболее релевантные данные для полностью связанного уровня для классификации.

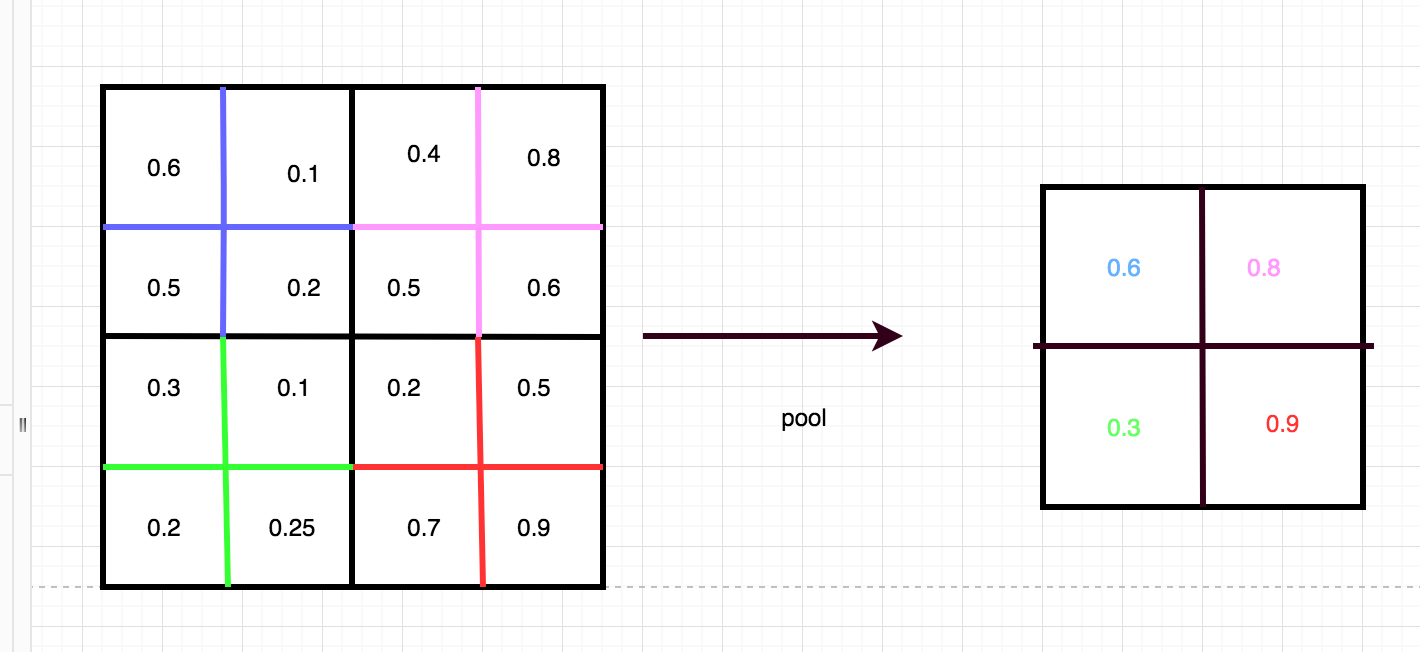
Для реализации вы устанавливаете значения для ширины, высоты и шага старого изображения и нового изображения. Следующим шагом является перебор изображения с использованием фильтра для извлечения объекта с максимальным значением, а затем вы возвращаете новый ввод уменьшенного размера.


Backprop:
Одна из наиболее важных причин создания CNN с нуля - получить из первых рук опыт вычисления backprop, поскольку это утечка абстракции. Это означает, что по мере усложнения систем разработчики полагаются на большее количество абстракций. Абстракции скрывают сложность, позволяя разработчику написать программное обеспечение, которое обрабатывает абстракцию вместо решения сложной проблемы, такой как исчезающий или взрывной градиент. Тем не менее, этот закон также гласит, что разработчики надежного программного обеспечения в любом случае должны изучить основные детали абстракции . Итак, давайте изучим это!
Прежде чем углубляться в то, как работает backprop в архитектуре CNN, я настоятельно рекомендую эту лекцию, в которой подробно расскажу о том, как работает backprop, для подробного объяснения.
Обратное распространение измеряет, как выходные данные изменяются с учетом входных данных. Цель обратного распространения - найти значения для весов, которые минимизируют результат функции потерь. Карта активации, выход сверточного слоя, является результатом фильтра и линейного преобразования, которые весовые коэффициенты применяют к входным данным. Поэтому нам нужно рассчитать градиент - насколько изменяется количество - по отношению к весам и по отношению к входным данным. Этот процесс выполняется для каждого пикселя на выходе, поскольку каждый вес в фильтре помогает создать каждый пиксель на выходе. Это указывает на то, что изменение весов изменит выходные пиксели. Таким образом, все эти изменения составляют в конечном итоге потери.
Для простоты графики и понимания интуиции я собираюсь использовать эти размеры, вход 3x3, фильтр 2x2 и выход 2x2. Частные производные для backprop, где W - вес, а H - выход, будут выглядеть так:

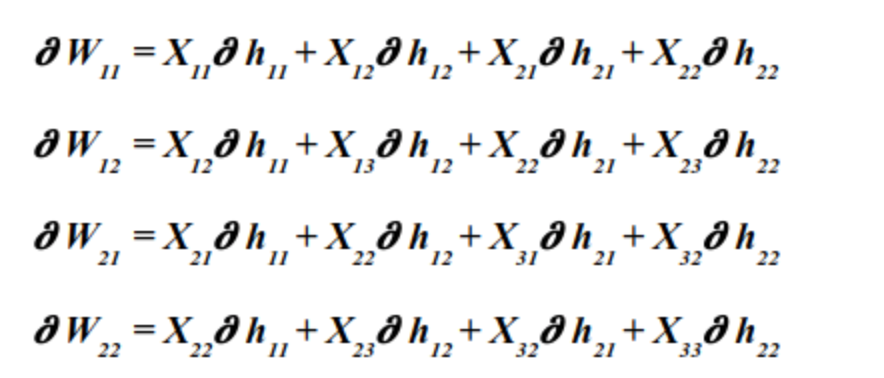
Чтобы реализовать код backprop для текущего слоя и почему работают вышеприведенные уравнения, важно понимать, что мы получаем градиент по отношению к выходным данным в качестве входных данных, и нам нужно вычислить градиент для весов и входных данных. Следовательно, градиент по отношению к входу (или градиент по отношению к выходу для предыдущего слоя) будет входным для обратного прохода предыдущего слоя. Эта связь является причиной того, что обратное распространение является мощным.

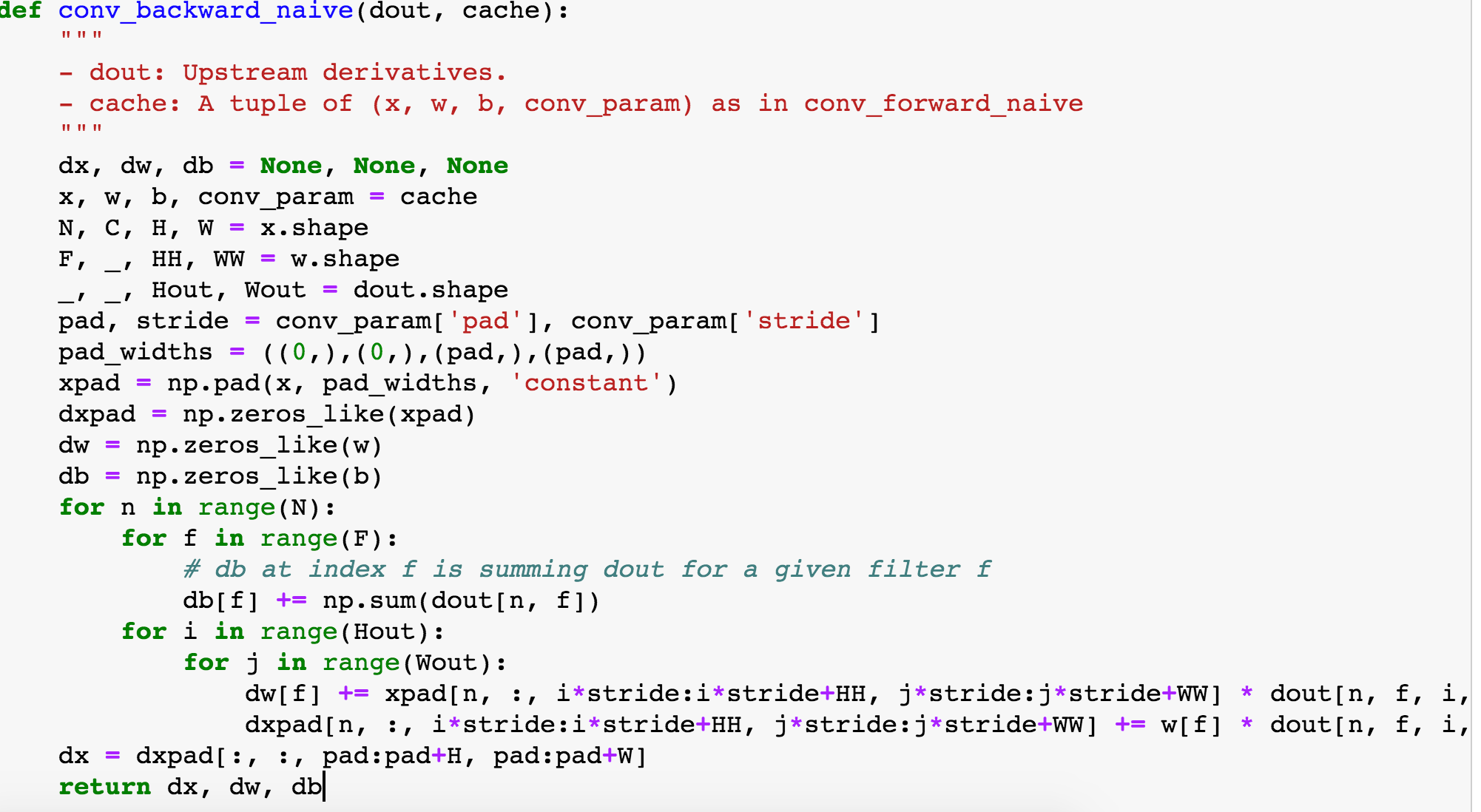
В конце концов, он проходит полный круг, поскольку обратное распространение для сверточного слоя также является сверткой, но с пространственно перевернутыми слоями.
Полностью связанный слой
Наконец, как только все свертки и пулы завершены, конечная часть сети становится полностью связным уровнем. Эта часть сети использует функции, извлеченные CNN, и передает их через прямую нейронную сеть для классификации. Полностью связанный слой более эффективен при использовании после свертки и объединения, поскольку он классифицирует набор объектов, которые были пространственно сохранены в процессе извлечения объектов. Это означает, что сеть будет давать более точные результаты, поскольку у нее более точные данные.


Комментарии
Отправить комментарий